Game History
Round: 5
Purchase Units - Italians
Italians buy 1 airfield, 3 armour and 3 infantry; Remaining resources: 0 PUs;
Combat Move - Italians
Trigger RailMovementAutoPlaceItalians: Italians has 1 Europe_Rail placed in Southern Italy
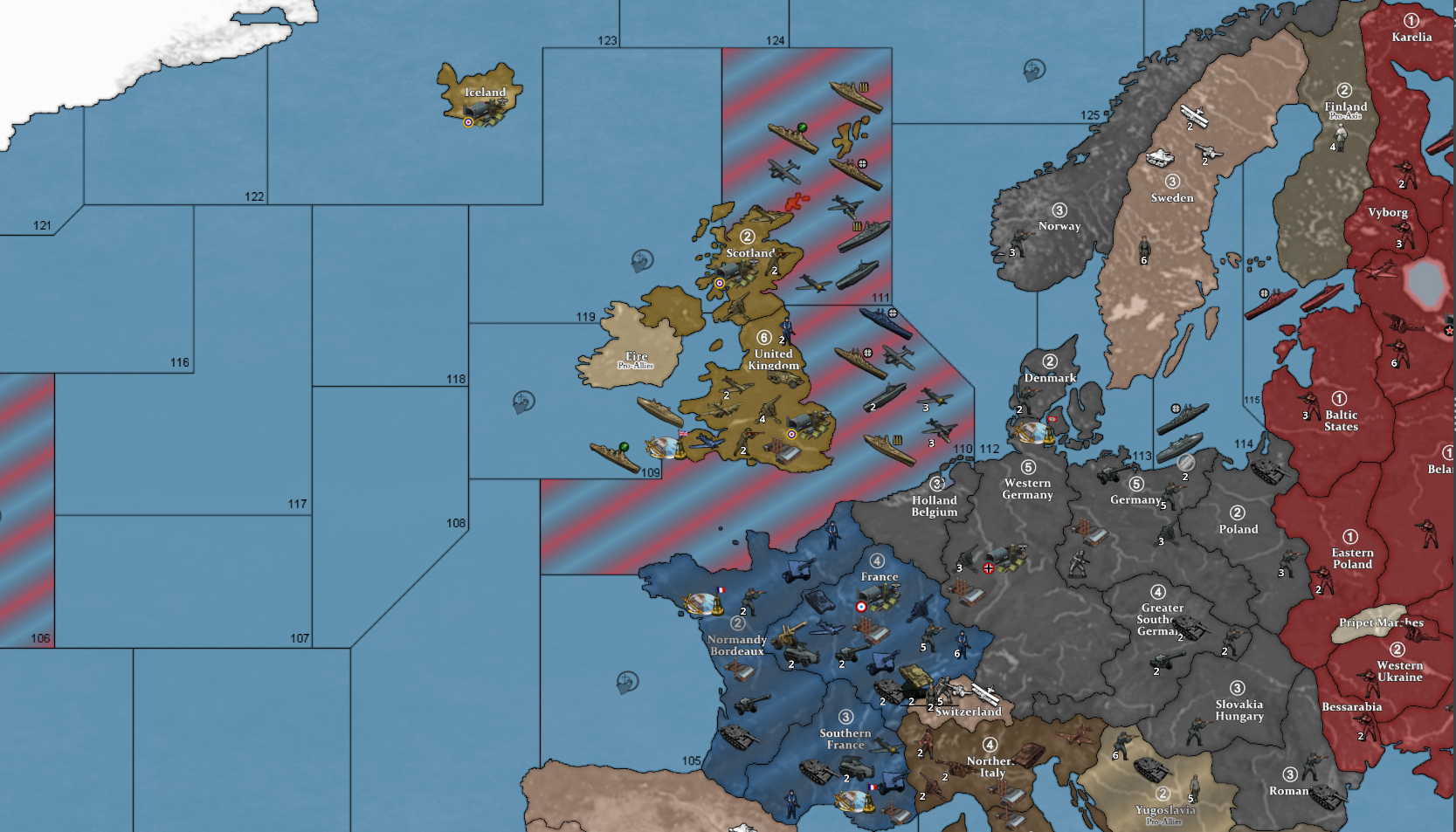
2 armour moved from Romania to Ukraine
1 bomber moved from Eastern Poland to Alexandria
1 fighter moved from Southern Italy to Alexandria
1 artillery and 1 infantry moved from Tobruk to Alexandria
1 armour moved from Northern Italy to 97 Sea Zone
1 infantry moved from Southern Italy to 97 Sea Zone
1 Escort_Convoy, 1 armour, 1 cruiser, 1 destroyer, 1 infantry and 1 transport moved from 97 Sea Zone to 98 Sea Zone
1 armour and 1 infantry moved from 98 Sea Zone to Trans-Jordan
Combat - Italians
Battle in Trans-Jordan
Italians attack with 1 armour and 1 infantry
British defend with 1 infantry
Italians roll dice for 1 cruiser in Trans-Jordan, round 2 : 1/1 hits, 0.50 expected hits
British roll dice for 1 infantry in Trans-Jordan, round 2 : 1/1 hits, 0.33 expected hits
1 infantry owned by the Italians lost in Trans-Jordan
1 infantry owned by the British lost in Trans-Jordan
Italians win, taking Trans-Jordan from British with 1 armour remaining. Battle score for attacker is 0
Casualties for Italians: 1 infantry
Casualties for British: 1 infantry
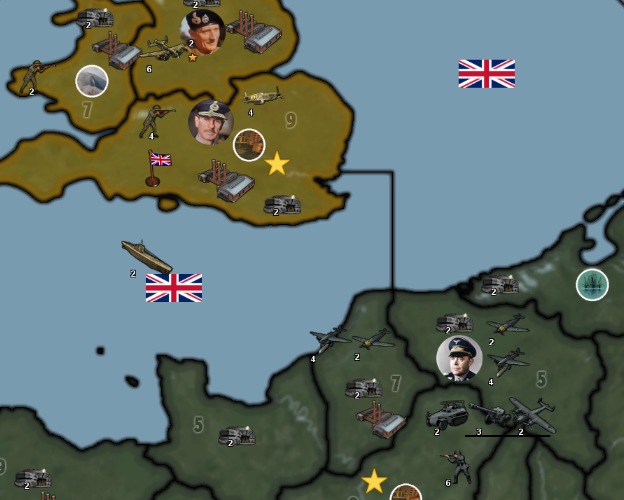
Battle in Alexandria
Italians attack with 1 artillery, 1 bomber, 1 fighter and 1 infantry
British defend with 1 infantry
Italians roll dice for 1 artillery, 1 bomber, 1 fighter and 1 infantry in Alexandria, round 2 : 1/4 hits, 1.83 expected hits
British roll dice for 1 infantry in Alexandria, round 2 : 0/1 hits, 0.33 expected hits
1 infantry owned by the British lost in Alexandria
Italians win, taking Alexandria from British with 1 artillery, 1 bomber, 1 fighter and 1 infantry remaining. Battle score for attacker is 3
Casualties for British: 1 infantry
Battle in Ukraine
Italians attack with 2 armour
Russians defend with 1 infantry
Italians roll dice for 2 armour in Ukraine, round 2 : 1/2 hits, 1.00 expected hits
Russians roll dice for 1 infantry in Ukraine, round 2 : 1/1 hits, 0.33 expected hits
1 armour owned by the Italians lost in Ukraine
1 infantry owned by the Russians lost in Ukraine
Italians win, taking Ukraine from Russians with 1 armour remaining. Battle score for attacker is -2
Casualties for Italians: 1 armour
Casualties for Russians: 1 infantry
Trigger Remove All Wolfpack: has removed 1 Wolfpack owned by Germans in 112 Sea Zone
Non Combat Move - Italians
Trigger Wolfpack at112 SeaZones: Germans has 1 Wolfpack placed in 112 Sea Zone
Turning on Edit Mode
EDIT: Turning off Edit Mode
Trigger RailMovementAutoPlaceRemoveItalians: has removed 1 Europe_Rail owned by Italians in Southern France
1 bomber and 1 fighter moved from Alexandria to Tobruk
1 armour moved from Yugoslavia to Romania
1 armour moved from Northern Italy to Romania
3 mine_unarmeds moved from Southern Italy to Northern Italy
1 Europe_Rail and 1 infantry moved from Southern Italy to Southern France
1 air_transport and 1 infantry moved from Southern Italy to Gibraltar
EDIT: 1 Italian_LCV moved from Gibraltar to Southern France
1 infantry moved from Bulgaria to Greece
1 infantry moved from Bulgaria to Romania
1 infantry moved from Romania to Bessarabia
Place Units - Italians
1 airfield placed in Gibraltar
3 armour and 3 infantry placed in Northern Italy
Turn Complete - Italians
Italians collect 18 PUs; end with 18 PUs
Trigger Italians AdvancedProduction: Italians met a national objective for an additional 3 Optional[PUs]; end with 21 Optional[PUs]
Objective Italians 1 Control The Mediterranean: Italians met a national objective for an additional 5 PUs; end with 26 PUs
Objective Italians 2 Roman Empire: Italians met a national objective for an additional 5 PUs; end with 31 PUs
Combat Hit Differential Summary :
Italians regular : -0.33
Russians regular : 0.67
British regular : 0.33
EXP-bvsb-7-1-26 I 4.tsvg